

以前、こちらの記事を書いたのでが、嫁に「全然わかんないんだけど」と言われてしまいました
なので今回は 初心者でも分かりやすいよう詳細に書き直しています
やりたいこととしてはGoogleアカウトがあれば無料で使用できる、スプレッドシートやGASを使用して、スクレイピングを行うことです
自分は購入した株の管理を行いたいがためにスプレッドシート/GASを利用しています
はじめに
まずは言葉の説明から
スクレイピング
簡単にいうと「特定のウェブページ上の、特定の情報(文字列など)を、機械的に取得すること」になります
株関連のサイトだと、あるの銘柄の現在の価格や利回りを機械的に取得する、ということです
機械的にというのはなんらかの仕組みを使用するのですが、方法は様々です
プログラムができるような方は Python など使いますが、この記事では比較的簡単なスプレッドシート/GASを使用した方法を紹介します
スプレッドシート
スプレッドシートは要するにブラウザで使用できる Excel です
Google アカウントがあれば無料で利用できるので、利用しない手はないです
機能的には Excel に劣るようですが、自分はそもそもそこまで Excel を使いこなしてないので、正直差分は感じてないです
むしろサーバー上にデータがあるので、いちいち共有などしなくてもどこからでも最新のスプレッドシートにアクセスできるなど、スプレッドシートの方が管理等しやすい印象があります
自分は株以外にも食事管理やトレーニング管理、資産管理なんかもスプレッドシートを使っています
GAS (Google Apps Script)
スプレッドシートで、より「かっこいい」ことをしたい場合に使用するもの、という認識でいいかと思います
正確にはスクリプト言語といって、プログラミングができますが、「スクリプト言語」とか「プログラミング」という単語に拒絶反応を起こす人もいるかと思うので、まずは、なんか複雑なことをする時に必要なんだなぁくらいの認識で良いかと思います
簡単なスクレイピングをするだけなら必要ないのですが、少々凝ったことをしていく場合に必要になります
この記事でも最終的には使用するものです
スプレッドシートのみでのスクレイピング
まずは GAS を使用しない、スプレッドシートのみでのスクレイピング方法を紹介します
こちらは割と一般的ですぐ調べられる情報かと思いますが、一応説明します
IMPORTXML 関数とは
Excel と同様でスプレッドシートでも関数を使用できます
IMPORTXML はスプレッドシートで使用できる関数で、「”特定のページ”から”特定の情報”を取得」できます
具体的には「”銘柄のページ”から”株価”を取得する」といったことができます
まさにスクレイピング用の関数ですね
XPath とは
IMPORTXML を使用する際、そのウェブページの URL と合わせて XPath が必要になります
XPath というのは簡単にいうと「ページ内の特定の情報の場所を示すアドレス」になります
もっと簡単に言うと「ウェブページの知りたい情報を示す住所」です
とりあえず、知りたい情報を取得するために必要なものなのね、でよいです
XPath の取得方法
Google Chrom での取得方法です
- ページで取得したい部分で右クリック ⇨ [検証] を選択、画面右側に開発者向け表示がされます
- [Elements] タブが選択されていると思うので、そこでカーソルを合わせながら、取得したい部分が選択される箇所を探します
- 選択される場所が特定できたらそこで右クリック ⇨ [Copy] ⇨ [Copy XPath] で XPath がクリップボードにコピーされます
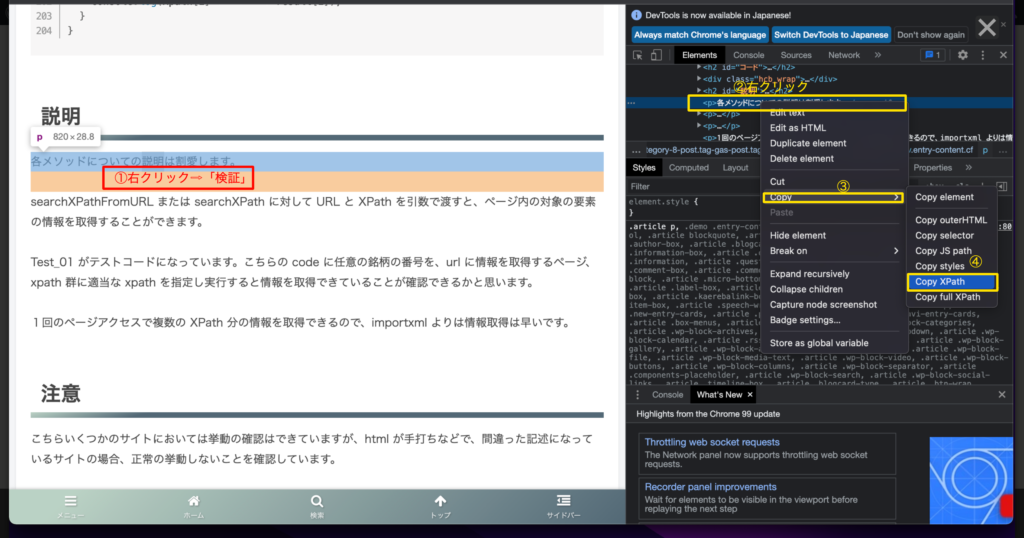
取得方法はいくつかあると思うので、詳しく知りたい方は検索してみてもよいかと思います
IMPORTXML の使い方
では、実際に使っていきます
手順は以下の通り
- スプレッドシートを開きます
- 取得した情報を表示したいセルを選択します
- セルに「=IMPORTXML(“<URL>”,”<XPath>”)」と入れます
- セルに取得した情報が表示されます
簡単な流れはこれだけです
例えば、かしおテックのページの一部を実際に取得する時は
=IMPORTXML("https://kasio.tech/8/2021/07/08/","//*[@id=""post-8""]/div/p[7]")
のような感じでスプレッドシートのセルに入力します
すると「各メソッドについての説明は割愛します。」と表示されるはずです
気を付ける点としては、URL、XPath ともに文字列として扱うので 「"」で囲みます
また、XPath にはそれ自体に「"」が使われているところがあるので、そこは「""」のように「"」を重ねておきます
「//*[@id="post-8"]/div/p[7]」が「"//*[@id=""post-8""]/div/p[7]"」になっています
IMPORTXML の問題点
IMPORTXML は URL と XPath さえわかっていれば簡単に情報を取得できるので便利です
ですが、取得したい情報って大体1つじゃないですよね?
同じページ中に複数ある場合が多いと思います
IMPORTXML は関数という性質上、一回呼び出すだけで内部処理でウェブページを開いてしまいます
例えば、スプレッドシートの複数のセルで同じ URL で IMPORTXML を呼び出すと、セルごとにページを開いていることになります
これ、一気に IMPORTXML が動いたりするとすごく反応が悪くなり、最悪タイムアウトして結局情報を取得できなかったりします
URL のサイトにも一気にアクセスを行うことになるので、負荷を与えてしまうことにもなります
ですので、本当に数個程度の情報を取得するくらいでしか、使用をおすすめしません
GAS を使用したスクレイピング
IMPORTXML は簡単に使用できる反面、多用すると情報取得が重くなるというデメリットがあります
これを解決するため GAS を使用した XPath での情報取得をしていきます
GAS でそのような機能を提供しているものがあるか調べたのですが、一般的には IMPORTXML ほど正確に取得できるものはありませんでした
なので、実際に取得する機能は自作しました
コードを公開しています
GAS を使ってみる
こちらの記事で初めて GAS を動かす際の手順を紹介しています
一度も触ったことのない方はこちらを見てみてください
コード
XPath による情報取得部分に実装コードを公開します
function getTag(str, offset)
{
var res = {};
res.begin = str.indexOf('<', offset);
res.end = str.indexOf('>', res.begin) + 1;
res.tag = str.slice(res.begin, res.end);
res.name = res.tag.replace('/','').replace('<','').replace('>','').split(' ')[0];
res.isClose = res.tag.indexOf('</') >= 0;
res.isComment = res.tag.indexOf('<!') >= 0;
res.isSingle = res.tag.indexOf('/>') >= 0;
return res;
}
function searchEnd(content, begin)
{
var end = begin;
var list = [];
var offset = begin;
while (true)
{
var res = getTag(content, offset);
if (res.begin < 0) break;
offset = res.end;
if (res.isSingle) continue;
if (res.isComment) continue;
if (res.isClose)
{
while (list.length > 0)
{
var name = list.shift();
if (name == res.name) break;
}
}
else
{
list.unshift(res.name);
}
if (list.length <= 0)
{
end = offset;
break;
}
}
return end;
}
function removeParentTag(content)
{
var begin = content.indexOf('>') + 1;
var end = content.lastIndexOf('<');
return content.slice(begin, end);
}
function searchId(content, hierarchy)
{
var id = hierarchy.replace('*[@','').replace(']','');
var index = content.indexOf(id);
return content.lastIndexOf('<', index);
}
function searchTag(content, hierarchy)
{
var array = hierarchy.replace('[', ',').replace(']', '').split(',');
var tag = array[0];
var count = 1;
if (array.length > 1)
{
count = parseInt(array[1]);
}
var begin = 0;
var list = [];
var offset = 0;
while (true)
{
var res = getTag(content, offset);
if (res.begin < 0) break;
offset = res.end;
if (res.isSingle) continue;
if (res.isComment) continue;
if (res.isClose)
{
while (list.length > 0)
{
var name = list.shift();
if (name == res.name) break;
}
}
else
{
if (list.length <= 0)
{
if (tag == res.name)
{
--count;
}
}
list.unshift(res.name);
}
if (count <= 0)
{
begin = res.begin;
break;
}
}
return begin;
}
function searchBegin(content, hierarchy)
{
var index = hierarchy.indexOf('@');
if (index < 0)
{
return searchTag(content, hierarchy);
}
return searchId(content, hierarchy);
}
function extractText(content)
{
var offset = 0;
var res = getTag(content, offset);
if (res.begin < 0)
{
return content;
}
var begin = searchTag(content, res.name);
var end = searchEnd(content, begin);
var remove = content.slice(begin, end);
return content.replace(remove, '');
}
function narrow(content, hierarchy)
{
if (hierarchy.length <= 0) return content;
if (hierarchy.indexOf('text()') >= 0)
{
return extractText(content);
}
var begin = searchBegin(content, hierarchy);
var end = searchEnd(content, begin);
var target = content.slice(begin, end);
return removeParentTag(target);
}
function searchXPath(content, xpath)
{
var result = [];
for (var i in xpath)
{
var target = content;
var array = xpath[i].split('/');
for (var j in array)
{
if (array[j].length <= 0) continue;
target = narrow(target, array[j]);
}
result.push(target);
}
return result;
}
function searchXPathFromURL(url, xpath)
{
var content = UrlFetchApp.fetch(url).getContentText('UTF-8');
return searchXPath(content, xpath);
}
function Test_01()
{
var code = XXXX;
var url = 'https://XXXX/stock/?code=' + code;
var market = '//*[@id="stockinfo_i1"]/div[1]/span'; // market
var name = '//*[@id="stockinfo_i1"]/div[1]/h2/text()'; // name
var industry = '//*[@id="stockinfo_i2"]/div/a'; // industry
var price = '//*[@id="stockinfo_i1"]/div[2]/span[2]'; // price
var eps = '//*[@id="kobetsu_right"]/div[3]/table/tbody/tr[3]/td[4]'; // eps
var dividend = '//*[@id="kobetsu_right"]/div[3]/table/tbody/tr[3]/td[5]'; // dividend
var yield = '//*[@id="stockinfo_i3"]/table/tbody/tr[1]/td[3]/text()'; // yield
var xpath = [market, name, industry, price, eps, dividend, yield];
var content = UrlFetchApp.fetch(url).getContentText('UTF-8');
var result = searchXPath(content, xpath);
for (var i in xpath)
{
console.log(xpath[i] + ' > ' + result[i]);
}
}
説明
searchXPathFromURL がメインとなる関数で、こちらを呼び出すことにより URL から情報を取得できます
その他の関数は searchXPathFromURL の機能を実装するためのものですので、処理の詳細を知りたい方以外は気にしなくて大丈夫です
searchXPathFromURL に URL と XPath の配列を渡すことで、各 XPath が示す情報を配列で取得できます
指定する URL ページ内の XPath の情報を取得することになります
使い方
Test_01 がテストコードになっているので、これを参考にしてみてください
こちらで定義している URL は適切なものに書き換える必要があります
XPath についても参照するページにおける正確なものを設定する必要があります
※追記(2023/4/13)

実行する際は上の画像の赤枠内を「Test_01」として実行してください
最初に実行するメソッドをちゃんと指定しないとエラーになります
補足
ちょっと詳しめな説明をします
実際にやっていることは
- ウェブページの HTML を文字列として取得
- 指定された XPath をもとに階層をたどり、タグ単位で絞り込む
- 指定部分まで階層をたどれたらそれを結果とする
といった内容です
HTML を保持し続けて、指定された XPath を全部探索するのでページアクセスは1回で済みます
なので IMPORTXML より最適な処理となっており、使用する際のパフォーマンスがいいです
問題点
プログラム自体の問題というよりか、アクセスするウェブページによるものです
対象のウェブページが手書きで構成されていたりして、HTML 構文が崩れている場合などは正常に機能しません
そういうページから情報を取得したい場合は、ちょっとしたカスタマイズが必要になると思います
まとめ
GAS による XPath 情報取得で IMPORTXML のデメリットは解決できたのではないか思います
実装自体半年以上前のものなので、よりよくすることはできそうです
時間があれば手を入れていきたいです
公開したコードを使用していただき、皆様の快適なスクレイピングが達成されることを願っております
実際にこのコードを使った株管理はこちらになります
より実践的な使い方をしているので参考にしてみてください!
質問について(2023.10 追記)
この記事が好評でして、質問をいくつか受けております
質問内容について答る記事を用意したので、こちらをご覧いただけたらと思います

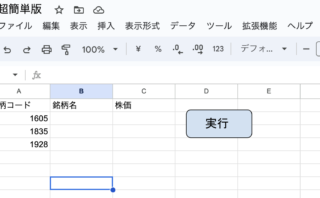
またスプレッドシートとの連携も行っている超簡易サンプルも用意しました
こちらも参考になになるかと思います

コメント
こんにちは。貴重な情報ありがとうございます!
記事の通りに進めたのですが、GASの実行ログで以下の文章が出まして、そこから進めません…。
何が原因かお分かりでしょうか?
エラー TypeError: Cannot read properties of undefined (reading ‘indexOf’)
getTag @ コード.gs:6
ちなみに、183行目は var code = 8001; に、
184行目のURLも、実際のURL(か○たん)に変更しています。
よろしくお願いします。
KAIさん
参考にして頂きありがとうございます!
改めて記事を確認してみましたが、記事内容に分かりづらいところがありましたので加筆しました。
確認お願いできますでしょうか。
貴重な情報ありがとうございます。
ひとつ質問ですが、同時に多数の株の株価を取りたいですが、183行目は var codeはどうすればいいですか?固定値にすればひとつの株しか取れないですか?すみませんが、回答をお願いします。
kasioさん
早速のご返答、ありがとうございます!
追記いただいた内容で、実行の確認ができました!
(初歩的なご質問、失礼致しました)
しかしながら、実行ログで確認できたそれぞれの値をセルに展開する方法が分からずでして…。
“Test_01()”では、セルには何も返していない?ようなので、別のスクリプトとの連携が必要だったりするのでしょうか?
別ページでご紹介頂いていた、こちらのURL(https://script.google.com/u/1/home/projects/1uZpw1r4fTiGTPU5bGkojLndDjpfxRI-ytnrEKuy3c8SKD54BGFoyCCYr/edit)を拝見しようとしたのですが、
GASのトップページ(https://www.google.com/script/start/)に飛んでしまい、内容が見れない状況です…。
不勉強で大変恐れ入ります。
よろしくお願いします。
お世話になります。
GASでXpathを使えないかと探して辿り着きました。
上記コードを用いることで、スプレッドシート上に情報を出力できるのでしょうか?
(例えばA2セルに銘柄コードを入力すると、B2セルに銘柄名、C2セルに市場を・・・というように)
素人なもので具体的な使い方まで理解できず…。ご教示頂けましたら幸甚です。